重複の削除
Distinctキーワードはデータから重複行を削除します。
Excelの「重複の削除」のようなことが出来ます。
あるいは「UNIQUE関数」も同じですね。
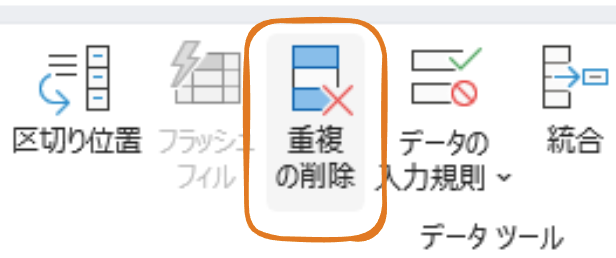
Distinct
Distinctの構文は以下のとおりです。
列名の前にDistinctを記載します。
select distinct 列名 from テーブル名
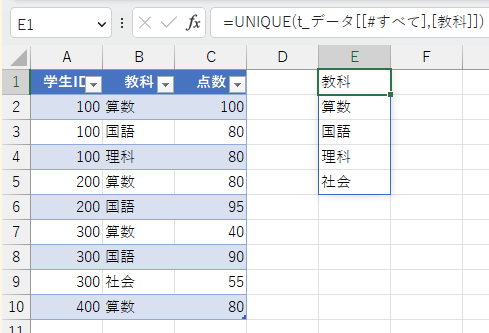
複数列でも同じように重複行の削除が出来ます。
複数列の場合でも列名の前に1つだけDistinctを記載すればOK。
少し元データを変更しました。
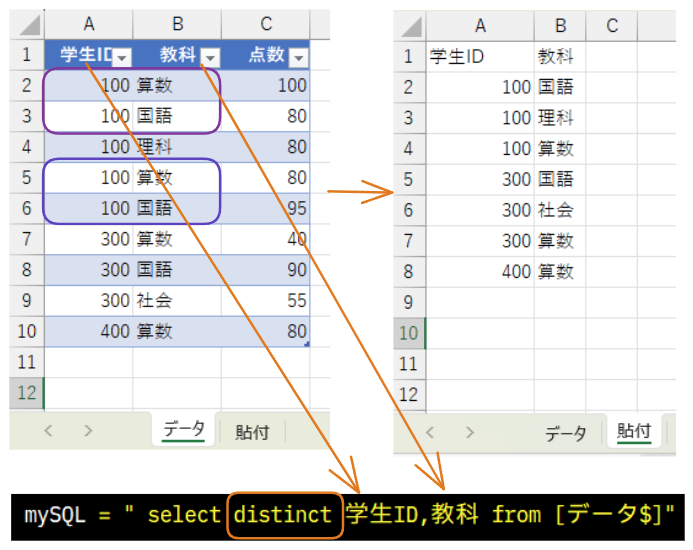
複数列でDistinctを使用した場合、指定した列のデータの組み合わせでユニークなものだけが抽出されます。
上記の例では学生IDと教科の組み合わせでユニークなもののみ抽出されます。
この例の場合「100,算数」と「100,国語」の組み合わせのみ重複していますので、それ以外のデータは全て抽出されています。
次回はWHERE句について紹介します。
ベースとなるコード
「SQL文」の欄を修正するだけで色々な集計が出来ます。