前回まで様々な集約関数を紹介してきました。
ここまでの集約関数の共通した使い方は 「列全体」 を集計対象としていたことです。
例えばCOUNT関数にしても列全体ではなく、列の要素ごとの集計を行いたい場合もあるでしょう。
そんなときはGROUP BY句です。
GROUP BY句とは
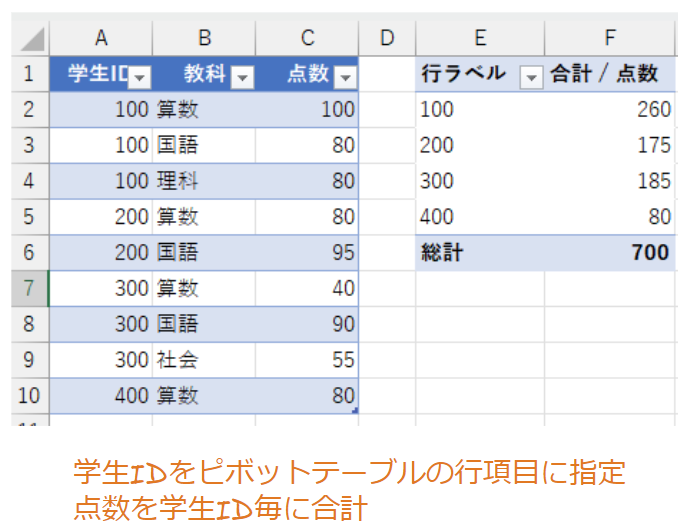
Excelでいうとピボットテーブルでの集計と同様のことが可能になります。
ピボットテーブルでは指定した要素でデータを集約し、集約した単位でデータを集計します。
GROUP BY句
SQLでピボットテーブルのような集計を行うにはGROUP BY句を使用します。
GROUP BY句の構文は以下のとおりです。
select 列名 from テーブル名 group by 列名
集約するキーとなる列を GROUP BY句に指定します。
ここまで紹介した構文では SELECT文には全列を意味する「*」を指定することができましたが、GROUP BYを使用した場合は指定することができません。
GROUP BY句を使用した場合は下記のみSELECT文に指定することができます。
- GROUP BY句で使用した列
- 集約関数
- 定数
GROUP BY句使用例
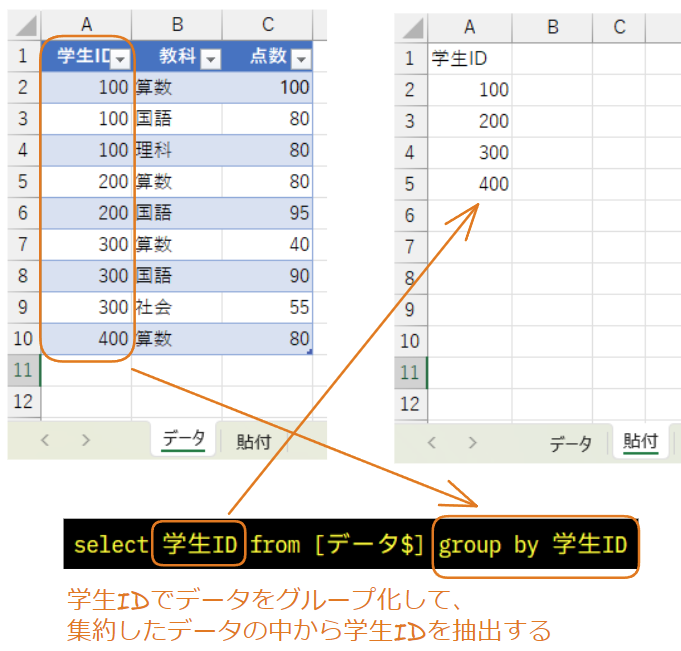
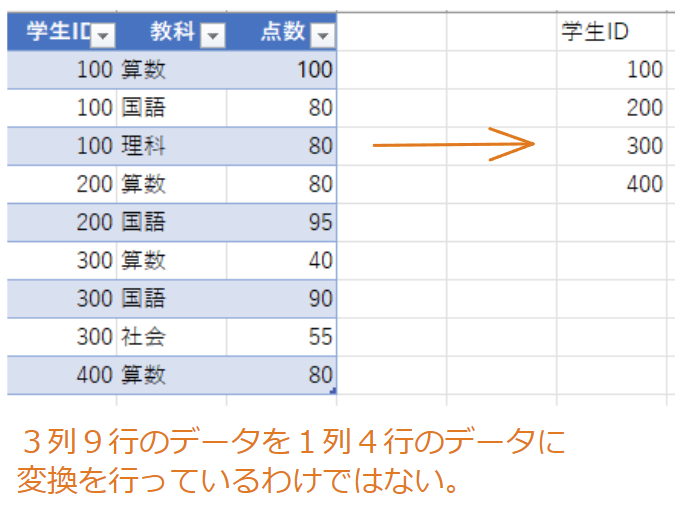
ここで気をつけたいのはGROUP BY句は決して下記の様な処理をしているわけではないということです。
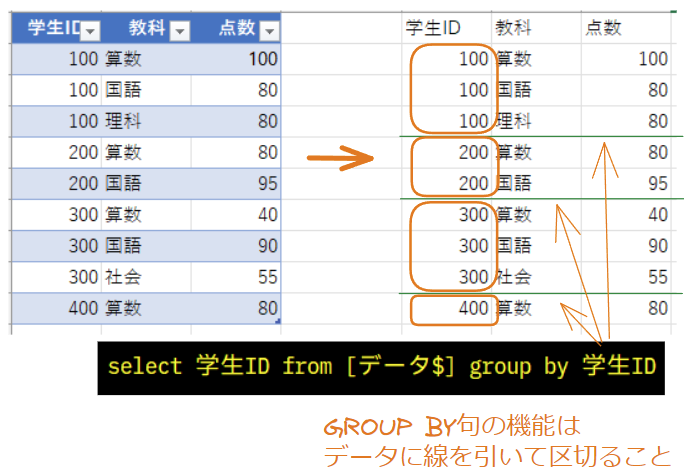
GROUP BY句の機能はデータに線を引いて範囲を区切ることです。
GROUP BY句に指定した列をSELECT文に指定すると重複のない状態(一意、ユニーク)で表示されます。
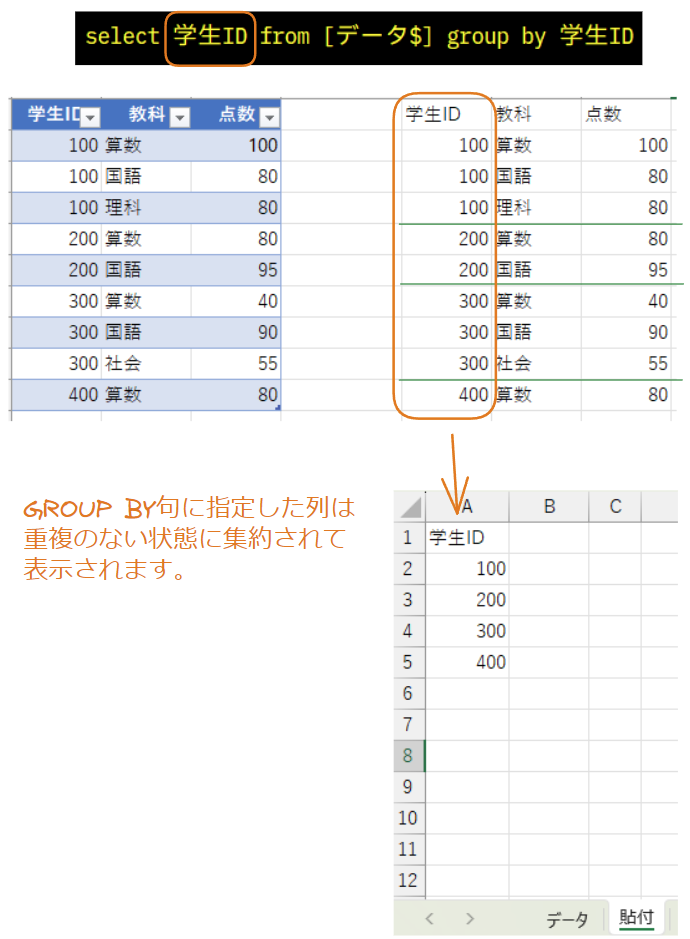
GROUP BY句を使用して集約関数と組み合わせてみます。
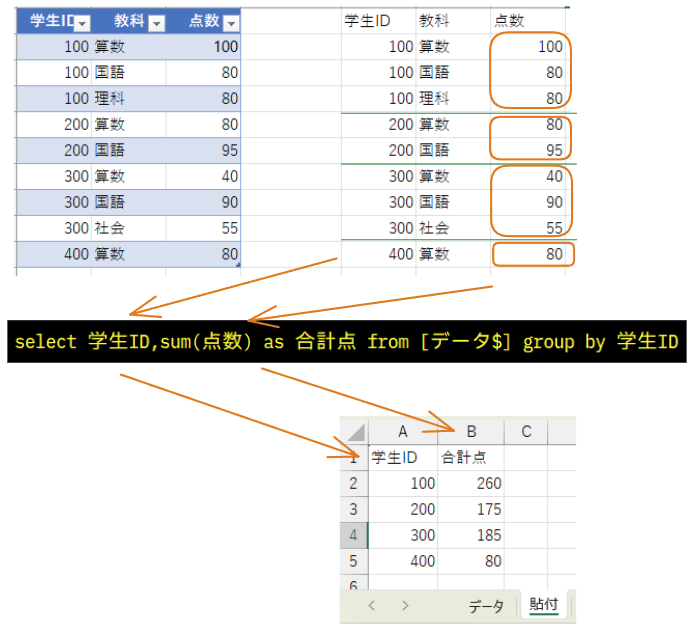
これまで集約関数を使用した場合、列全体を集計対象としていました。
しかしGROUP BY句を使用すると、集計対象がGROUP BY句で区切られた範囲毎に集計が行われるようになります。
今回の例では学生IDをGROUP BY句に指定していますので、学生ID毎にSUM関数の集計が行われます。
GROUP BY句の機能はデータを指定単位に集約することではない。
あくまでデータを区切ること。
これを理解しておけば集約関数や今後紹介するHAVING句の理解に繋がります。
次回はHAVING句を紹介していきます。